Importar Archivos de Texto Delimitados a SPSS
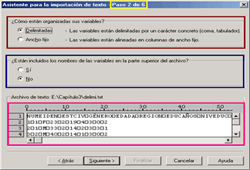
Para continuar con la extracción de los datos hacemos clic en el botón Siguiente, con lo que aparece el cuadro de diálogo correspondiente al paso 2 Tipo de archivo [Fig.3-38]. En este paso el asistente de importación nos hace dos preguntas concernientes al formato de los datos; la primera corresponde a ¿Cómo están organizadas sus variable?, para lo cual nos da dos posibilidades; Delimitada (Las variables están delimitadas por un carácter concreto [coma, tabulador]) y Ancho fijo (Las variables están alineadas en columnas de ancho fijo).
La segunda pregunta corresponde a ¿Están incluidos los títulos de las variables en la parte superior del archivo?, para lo que nos ofrece dos posibles respuestas SI o No.
Para poder determinar como están organizadas las variables dentro del archivo, debemos observar el contenido del visor de datos [Fig.3-39] y tratar de identificar si las variables están separadas por un carácter común o por el contrario tiene un número específico de columnas por variable. Si nos fijamos en los datos del visor, notaremos que las variables se encuentran separadas por un cuadrado (![]() ), el cual representa en SPSS al tabulado, con lo que podemos determinar que las variables están delimitadas por tabulaciones. Es importante recordar el carácter (
), el cual representa en SPSS al tabulado, con lo que podemos determinar que las variables están delimitadas por tabulaciones. Es importante recordar el carácter (![]() = Tabulador), ya que en los pasos siguientes, el asistente necesitará que lo especifiquemos. Una vez definido el tipo de archivo, debemos seleccionar la opción Delimitado en la primera pregunta.
= Tabulador), ya que en los pasos siguientes, el asistente necesitará que lo especifiquemos. Una vez definido el tipo de archivo, debemos seleccionar la opción Delimitado en la primera pregunta.
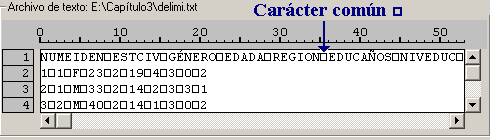
Después de comprobar el formato de las variables, debemos comprobar si el nombre de las variables se encuentra en la parte superior del archivo. Para realizarlo, nos remitirnos nuevamente al visor de datos y tratamos de detectar si en la primera fila de datos se incluyen los nombres de las variables. Si nos fijamos en los datos, notaremos que efectivamente los nombres de las variables son incluidos en el archivo, por lo tanto seleccionamos la opción Si en la segunda pregunta.
Una vez definido el formato del archivo hacemos clic en Siguiente, con lo que aparece el cuadro de diálogo correspondiente al paso 3 [Fig.3-40]; en este cuadro el asistente nos realiza tres preguntas sobre la forma de los casos. La primera de las preguntas corresponde a ¿En qué número de línea comienza el primer caso de los datos?, por defecto el programa declara la segunda línea como la fila de inicio de los casos, esto se debe a que en el paso anterior le especificamos al asistente que los nombres de las variables se encontraban en la primera fila, de lo contrario el primer caso se hallaría en la primera fila del archivo.
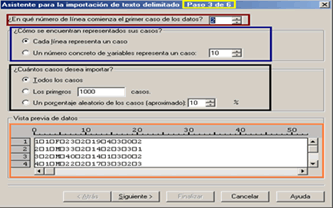
Si nos fijamos en el visor de datos, observaremos que los nombres de las variables han desaparecido, debido a que en el paso anterior se definió que la primera fila correspondía a los nombres de las variables; esta nueva visualización se presta para confusiones sobretodo en la primera pregunta; sin embargo el programa no permite seleccionar la primera fila como inicio de los casos y si intentamos ingresar el número uno (1) en la casilla, aparece la leyenda La primera fila de datos debe ser al menos una, o dos si están presentes los nombres de las variables.
La segunda pregunta corresponde a ¿Cómo se encuentran representados sus casos? y nos ofrece dos opciones Cada línea representa un caso y Un número concreto de variables representa un caso (para lo cual activa una casilla donde se específica la cantidad de variables). Generalmente los archivos delimitados contienen un caso por línea; si no se tiene certeza de cómo están representados los casos, se debe observar la casilla visor de datos para determinarlo.
Si los datos mantienen un orden a través de todas las filas incluyendo los separadores (Tabulaciones), podemos estar seguros que las variables están representando un caso por fila, de lo contrario es necesario ir a la fuente de los datos para determinarlo; es decir, acudir al creador del archivo ya que los casos están determinados por un número específico de variables. En nuestro caso cada fila representa un caso, por lo que seleccionamos la primera opción.
La tercera pregunta corresponde a ¿Cuántos casos desea importar?. Esta opción nos permite limitar el número de casos que serán extraídos del archivo de texto. Se puede importar el total de los datos, un número especifico de casos o un porcentaje de los datos. Si se escoge la opción del porcentaje, el programa aproxima este valor al número entero de casos más cercano y los selecciona de forma aleatoria. Por defecto esta pregunta se encuentra en la opción Todos los casos, ya que generalmente se importa toda la información del archivo. Dado que nos interesa importar toda la información, mantenemos la primera opción.