Añadir Variables en SPSS - 2da Parte
Después de comprobar que los archivos cumplen con los requerimientos del programa, estamos listos para comenzar con la fusión de los archivos. Lo primero que debemos hacer es abrir uno de los archivos en el editor de datos (en este caso, ya se encuentra abierto el archivo Electro.sav).
Una vez abierto, nos dirigimos al menú Datos, ubicamos la opción Fundir archivos y seleccionamos el procedimiento Añadir variables. [Fig.3-119]. Al surgir la ventana de navegación, ubicamos el archivo secundario o externo (en este caso Hogar.sav) y hacemos clic en abrir con lo que aparece el cuadro de diálogo correspondiente Añadir variables de [Fig.3-120], el cual nos indica el nombre del archivo del que se están importando las variables.
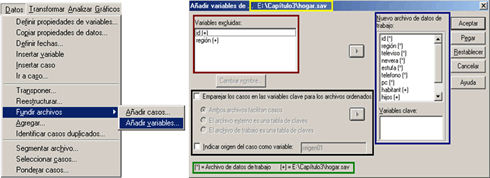
Este cuadro de diálogo se encuentra dividido en cuatro secciones; la primera de ellas corresponde a Variables excluidas, en donde encontraremos un listado de las variables que han sido separadas del archivo de datos fusionado. Por defecto, la lista contiene los nombres de las variables del archivo externo que duplican los del archivo de trabajo. Si se desea incluir en el archivo fusionado una variable excluida con un nombre duplicado, es necesario cambiar el nombre de la variable y añadirla a la lista de variables del nuevo archivo de trabajo, haciendo clic en el botón Flecha (![]() ) que aparece al costado derecho de la casilla.
) que aparece al costado derecho de la casilla.
La segunda sección la componen el Nuevo archivo de datos de trabajo, en donde se muestra un listado de las variables que se van a incluir en el nuevo archivo de datos fusionado. Por defecto, el programa incluye en la lista todos los nombres de variable únicos que existan en ambos archivos (Trabajo y Externo), así como una de las variables que tengan el mismo nombre en los dos archivos.
Adicionalmente incluye las variables de control, las cuales utiliza para emparejar los casos de los dos archivos. En el suceso que uno de los archivos cuente con más casos que el otro, el nuevo archivo de datos los incluye, pero sólo contendrá información para los casos del archivo que los proporcione, mientras que para los casos del otro archivo ingresa valores perdidos por el sistema; es decir, casillas vacías.
La tercera sección la componen las Opciones de fusión, en donde encontramos el botón Cambiar nombre, el cual utilizamos para modificar el nombre de las variables que serían excluidas. En esta sección también aparece la opción Emparejar los casos en las variables clave para los archivos ordenados, en donde hallamos tres posibilidades; Ambos archivos facilitan casos, archivo externo es una tabla de claves y el archivo de trabajo es una tabla de claves.
La opción ambos archivos facilitan casos nos permite indicarle al programa que los dos archivos cuentan con casos únicos y por lo tanto no aparecen en el otro; al seleccionar esta opción es indispensable definirle al programa una variable clave que le permita al archivo determinar el orden de emparejamiento de los casos o de lo contrario no es posible realizar el procedimiento.
Es necesario resaltar que una tabla de claves o tabla de referencia, es un archivo en el que los datos de cada "caso" se pueden aplicar a varios casos del otro archivo de datos. Por ejemplo, si un archivo contiene información sobre los diferentes miembros de la familia (como el sexo, la edad, la formación) y el otro contiene información global (como los ingresos totales, el número de miembros o la ubicación), se puede utilizar el archivo global como una tabla de referencia y aplicar los datos comunes de la familia a cada uno de sus miembros en el archivo fusionado.
Una de las características principales de los archivos de claves es el reducido número de casos que contienen, ya que su utilidad radica en poder disminuir la cantidad de registros dentro del archivo. La tercera parte de esta sección corresponde a Indicar el origen del caso como variable, esta opción genera una nueva variable en el archivo de resultado en donde ubicará un valor 0 a los casos del archivo de trabajo y un valor 1 a los casos del archivo externo o secundario; además cuenta con una casilla para la asignación del nombre de la variable de identificación.
Por último encontramos la sección de especificación de archivos, en donde aparecen dos leyendas que nos informan la procedencia de las variables; es decir, nos indica el archivo en el que se localiza la variable. Para esta función el programa emplea dos marcadores; el primero corresponde al Asterisco (*), quien identifica a las variables procedentes del archivo de datos de trabajo o archivo al cual le estamos importando la información; el segundo marcador es el signo Suma (+), quien identifica las variables del archivo secundario o externo, a quien se le extraerá la información.
Para continuar con el ejemplo activaremos la opción Indicar el origen del caso como variable, dejando estipulado el nombre Origen; sucesivamente seleccionaremos la opción Ambos archivos facilitan casos, por lo que seleccionamos en la casilla de variables excluidas la variable ID y la ingresamos en la casilla Variables clave; para realizarlo es necesario resaltar la variable y posteriormente hacer clic en el botón flecha (![]() ) ubicado en la parte inferior del cuadro, al costado izquierdo de la casilla variables clave, de manera que obtenemos los resultados de la figura [3-121].
) ubicado en la parte inferior del cuadro, al costado izquierdo de la casilla variables clave, de manera que obtenemos los resultados de la figura [3-121].
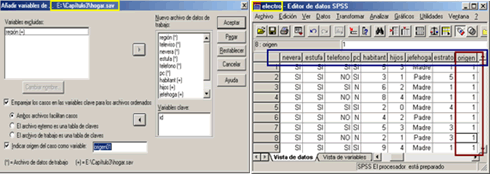
Después de seleccionar la opción hacemos clic en Aceptar con lo que aparece la leyenda (Advertencia: La correspondencia indicada fallará si los datos no se ordenan por orden ascendente respecto a las variables clave); nuevamente hacemos clic en Aceptar con lo que el procedimiento se realiza y las variables se representan en el editor de datos de SPSS [Fig.3-122].
Si nos fijamos en la variable Origen, notaremos que todos los valores se encuentran en 1, esto se debe a que todos los casos se importaron las variables del archivo externo; al igual que en el ejemplo anterior es necesario guardar el archivo de resultado con otro nombre o si no perderemos la información original. Es necesario resaltar que las variables del archivo de datos de resultado contendrá las propiedades definidas en los archivos de origen.
En conclusión la opción Añadir variables nos permite unir la información de dos archivos cuyas variables estén relacionadas, siempre que sus casos correspondan a los mismos sujetos u observaciones. Además este procedimiento nos permite aplicar en el archivo de resultado las propiedades definidas para cada una de las variables en su archivo de origen.