Fundir Archivos de SPSS - Añadir Casos
Es posible que en algunas ocasiones se cuente con información complementaria distribuida en varios archivos de datos, lo que impide realizar un análisis con la totalidad de la información, debido a que SPSS únicamente nos permite tener un solo archivo de datos abierto a la vez. Para poder generar análisis con el total de la información, es necesario aglomerar los datos (Variables y casos) de las diferentes fuentes dentro de un único archivo.
Para esta labor SPSS cuenta con un procedimiento que nos permite congregar información proveniente de diferentes archivos, con la condición que el proceso se realice en pares de ficheros; es decir, sólo podemos reunir información de dos archivos por cada proceso de fusión que se ejecute.
Para la unión de información, el procedimiento nos ofrece dos posibilidades, la primera consiste en agregar los casos o respuestas de una fuente externa dentro del archivo principal y la segunda consiste en importar las variables y sus respectivas respuestas desde una fuente externa. Cada una de estos procedimientos cuenta con unos criterios que se deben cumplir para su correcto funcionamiento, los cuales conoceremos en los apartados siguientes.
Agregar o añadir Casos
Este procedimiento se utiliza cuando se cuenta con dos o más archivos con el mismo tipo de variables o preguntas y cuya única diferencia radica en las respuestas o casos. Un ejemplo de este tipo de archivos pueden ser las ventas regionales de un producto, las encuestas realizadas a personas de diferentes departamentos de un país, etc. Para poder comprender los pasos que se deben ejecutar en la fusión de información, realizaremos a manera de ejemplo la unión de los casos de los archivos hogareste.sav y hogarsur.sav incluidos en la carpeta Capítulo3 del CD adjunto, los cuales contienen información de una encuesta realizada en cien (100) hogares de cada región.
Para poder realizar la fusión de archivos con variables iguales y casos diferentes, es necesario abrir primero uno de los archivos en el Editor de datos de SPSS, ya sea por medio del menú Archivo..Abrir...Datos ó mediante el icono Abrir (![]() ). En nuestro caso utilizaremos el archivo hogareste.sav como archivo de destino, por lo que es necesario abrirlo en el editor de datos. Una vez abierto el archivo, elegimos en el menú Datos la opción Fundir archivos y dentro de ella seleccionamos el procedimiento Añadir casos [Fig.3-110]. Al hacer clic en él, aparece una ventana de navegación en donde ubicamos el archivo externo, del cual vamos a extraer la información, que para el caso corresponde a hogarsur.sav y se encuentra ubicado en la carpeta Capítulo3 del CD adjunto [Fig.3-111].
). En nuestro caso utilizaremos el archivo hogareste.sav como archivo de destino, por lo que es necesario abrirlo en el editor de datos. Una vez abierto el archivo, elegimos en el menú Datos la opción Fundir archivos y dentro de ella seleccionamos el procedimiento Añadir casos [Fig.3-110]. Al hacer clic en él, aparece una ventana de navegación en donde ubicamos el archivo externo, del cual vamos a extraer la información, que para el caso corresponde a hogarsur.sav y se encuentra ubicado en la carpeta Capítulo3 del CD adjunto [Fig.3-111].
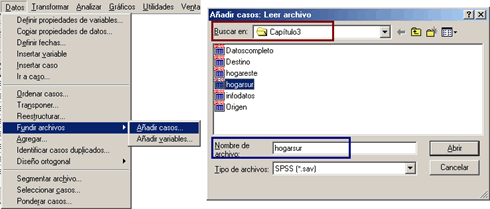
Después de localizar el archivo, lo seleccionamos y hacemos clic en Abrir, con lo que aparece el cuadro de diálogo correspondiente Añadir casos desde [Fig.3-112]; note como en la parte superior del cuadro se hace referencia a la ubicación y nombre del archivo externo, de donde serán extraídos los casos.
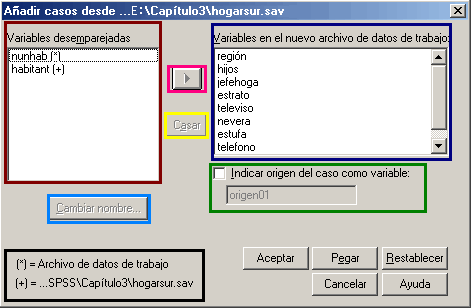
Este cuadro se encuentra dividido en tres secciones; la primera corresponde a la lista de variables desemparejadas, en donde aparecen las variables que por algún motivo no se encuentran en los dos archivos. Generalmente son dos los factores que causan su aparición, ya sea por que tienen nombres diferentes en cada uno de los archivos (EJ: NÚMHAB y HABITANT estas dos variables hacen referencia al número de habitantes de un hogar y su diferencia radica en el nombre que se le asigno en cada archivo); la segunda razón es por la existencia de variables únicas en cada archivo, es decir variables que fueron creadas en uno de los archivos pero omitidas en el otro.
Adicionalmente, se suelen incluir en este listado las variables que no tengan el mismo tipo de caracteres definido así su nombre coincida en ambos archivos (Ej: una variable de cadena con una numérica), así como también las variables de cadena que contengan diferente longitud de caracteres.
La segunda sección del cuadro corresponde a Variables en el nuevo archivo de datos de trabajo; en esta casilla encontraremos las variables que han coincidido en los dos archivos, la única condición que han cumplido estas variables es tener el mismo nombre y el mismo tipo de datos (Numérico o Cadena) en los dos archivos. Si nos fijamos en el listado observaremos que cada una de las variables cuenta con un nombre único y no se encuentran duplicados; esto se debe a que el programa reúne los casos de los dos archivos en una sola variable y le asigna el nombre que aparece en los dos archivos.
La tercera sección del cuadro corresponde a especificación de archivos, en donde encontramos dos leyendas que nos informan la procedencia de las variables. Para la identificación, el programa utiliza dos marcadores, el primero corresponde al Asterisco (*), quien identifica a las variables procedentes del archivo de datos de trabajo (archivo que se encuentra abierto en el editor de datos), al cual le estamos importando la información. El segundo marcador es el signo Suma (+), quien identifica las variables del archivo externo o archivo al que se le extraerá la información.
Además de las secciones, encontramos en el cuadro cuatro opciones adicionales correspondientes a Cambiar Nombre; esta opción nos permite modificar el nombre de una variable, generalmente se manipula el nombre de una variable para generar una pareja, es decir se le asigna el nombre de una de las variables del otro archivo, con el fin de facilitar el reconocimiento de la variable en el archivo resultante.
Casar, esta opción nos permite unir el contenido de dos variables con diferentes nombres siempre que sean de archivos diferentes; generalmente la utilizamos para definir una pareja de datos. Indicar el origen del caso como variable; esta opción genera una nueva variable en el archivo de resultado, en donde ubicará un valor 0 a los casos del archivo de trabajo y un valor 1 a los casos del archivo externo o secundario; además cuenta con una casilla para la asignación del nombre de la variable de identificación.
Por último encontramos el icono Flecha (![]() ), con el cual podemos agregar al archivo de resultado las variables desemparejadas que deseemos, esta opción la utilizamos en las variables que no se encuentran en los dos archivos, es decir variables no relacionadas.
), con el cual podemos agregar al archivo de resultado las variables desemparejadas que deseemos, esta opción la utilizamos en las variables que no se encuentran en los dos archivos, es decir variables no relacionadas.
Para continuar con el ejemplo, vamos a definir como una pareja las variables NUMHAB y HABITANT, para realizarlo debemos seleccionar las dos variables por lo que hacemos clic en una de las variables y luego hacemos (Ctrl + clic) en la otra. Este método es de bastante utilidad ya que generalmente aparece un gran listado de variables desemparejadas y la selección de variables se hace tediosa.
Después de seleccionar las variables (Resaltarlas), hacemos clic en Casar con lo que las variables pasaran a la casilla de variables en el nuevo archivo de datos de trabajo; para terminar activamos la opción Indicar origen del caso como variable y le especificamos el nombre origen [Fig.3-113] y posteriormente hacemos clic en Aceptar con lo que aparecerá el archivo resultante en el editor de datos [Fig.3-114].
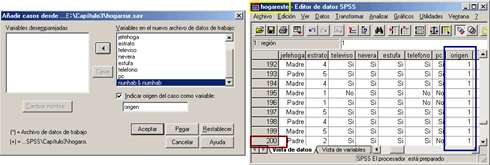
Si nos fijamos en el editor de datos, observaremos que el número de casos ha pasado a la cifra de doscientos casos (200), así mismo notaremos que en la parte final de las columnas de variables, aparece la variable Origen. Además, si nos fijamos en el nombre del archivo de resultado, notaremos que esta representado con el nombre de Hogareste, debemos tener mucho cuidado en el momento de guardar el archivo, ya que si no se le asigna un nuevo nombre perderemos la información original del archivo Hogareste; para evitar este inconveniente lo guardaremos bajo el nombre de Hogares en la carpeta Mis documentos de la unidad [C:].
Es importante resaltar que este procedimiento lo utilizamos para reunir la mayor cantidad posible de información, pero es recomendable mantener los archivos originales intactos, ya que generalmente se le hacen análisis a cada uno de ellos para comparar los resultados.