Barra de herramientas de SPSS en Español
Buscar (![]() ): A través de este icono podemos ubicar un valor dentro de una variable; es decir, nos permite encontrar un número o una combinación de caracteres dentro de los registros de una variable. Dado que generalmente se utilizan números para representar las categorías de las variables (Por ejemplo: hombre = 0 y mujer =1) y las bases de datos poseen múltiples variables, sería ilógico esperar que la búsqueda se realice en todo el archivo.
): A través de este icono podemos ubicar un valor dentro de una variable; es decir, nos permite encontrar un número o una combinación de caracteres dentro de los registros de una variable. Dado que generalmente se utilizan números para representar las categorías de las variables (Por ejemplo: hombre = 0 y mujer =1) y las bases de datos poseen múltiples variables, sería ilógico esperar que la búsqueda se realice en todo el archivo.
Al seleccionar el procedimiento Buscar, aparece un nuevo cuadro de diálogo [Fig.1-25]; para identificar la variable en la que se realizará la búsqueda, el cuadro adiciona en la parte superior la frase “Buscar datos en la variable ***” (donde *** = nombre de la variable). Para seleccionar una variable se debe hacer clic sobre ella directamente en el editor de datos, de manera que el nombre de la variable en la frase cambie por el de la variable seleccionada.
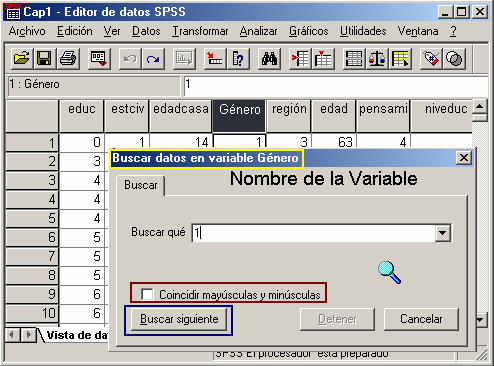
Si nos fijamos en el cuadro de diálogo Buscar datos, notaremos que aparece en la parte inferior del cuadro la opción Coincidir mayúsculas y minúsculas; esta opción nos permite especificarle al programa que realice la búsqueda de forma más exacta; desde luego esta opción sólo es aplicable a las variables que tengan caracteres alfanuméricos (Letras). Por último encontramos el botón Buscar siguiente; a través de este botón podemos pasar de un caso o registro encontrado, que coincida con las condiciones de búsqueda, al siguiente.
Insertar caso (![]() ) e Insertar variable (
) e Insertar variable (![]() ): Como su nombre lo indica, estas dos opciones nos permiten ingresar un nuevo Caso o Variable. Al seleccionar la opción Ingresar caso, el programa nos permite ingresar los valores del caso para cada una de las variables del archivo. Si por el contrario seleccionamos la opción Insertar variable, el programa nos permite ingresar una nueva variable o pregunta para los casos del archivo de datos activo.
): Como su nombre lo indica, estas dos opciones nos permiten ingresar un nuevo Caso o Variable. Al seleccionar la opción Ingresar caso, el programa nos permite ingresar los valores del caso para cada una de las variables del archivo. Si por el contrario seleccionamos la opción Insertar variable, el programa nos permite ingresar una nueva variable o pregunta para los casos del archivo de datos activo.
Segmentar archivo (![]() ): Este icono nos permite dividir nuestra base de datos (Archivo activo) en distintos grupos de acuerdo a la variable que utilicemos para la segmentación. Al seleccionar esta opción, se abre un nuevo cuadro de diálogo [Fig.1-26]; en el que encontramos tres diferentes opciones de segmentación. La primera opción del cuadro es Analizar todos los casos, no crear los grupos; esta opción nos permite trabajar con todos los casos de la base y calcular los resultados de los estadísticos empleando la totalidad de los casos u observaciones.
): Este icono nos permite dividir nuestra base de datos (Archivo activo) en distintos grupos de acuerdo a la variable que utilicemos para la segmentación. Al seleccionar esta opción, se abre un nuevo cuadro de diálogo [Fig.1-26]; en el que encontramos tres diferentes opciones de segmentación. La primera opción del cuadro es Analizar todos los casos, no crear los grupos; esta opción nos permite trabajar con todos los casos de la base y calcular los resultados de los estadísticos empleando la totalidad de los casos u observaciones.
La segunda opción corresponde a Comparar los grupos; esta opción nos permite comparar los resultados de los procedimientos que se realicen con el programa para las categorías de la variable de agrupación; para realizar la comparación el programa realiza los cálculos solamente con los datos de cada categoría y presenta los resultados de forma comparativa; es decir ubica de forma jerárquica los resultados de cada categoría (por ejemplo: tabla categoría 1, tabla categoría 2, gráfico categoría 1, gráfico categoría 2, estadístico categoría 1, estadístico categoría 2).
La tercera opción corresponde a Organizar los resultados por grupos; esta opción es muy similar a la opción anterior, con la diferencia que los resultados de los procedimientos que se realicen con el programa se representan en forma organizada (Por ejemplo: Tabla Cat1, Gráfico Cat1, Estadístico Cat1, Tabla Cat2, Gráfico Cat2, Estadístico Cat2). Esta opción es bastante útil si nosotros deseamos hacer un análisis separado de la muestra por algún tipo de “rangos”, como por ejemplo el género, la región, la fecha, etc.
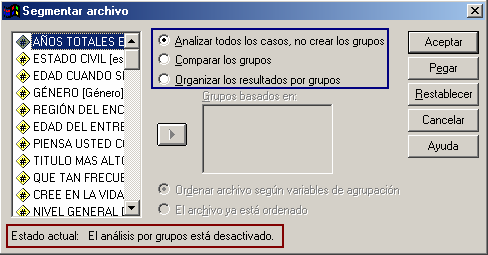
Para realizar la segmentación de archivo debemos seleccionar una de las dos últimas opciones, de manera que se active la casilla “Grupos basados en”; una vez se activa se ingresa en ella la variable o las variables que deseamos utilizar como rango y finalmente hacemos clic en Aceptar. Después de segmentar el archivo, cada procedimiento (tablas, gráficos o estadísticos) que se realice con el programa, mostrará los resultados de acuerdo a la segmentación. En capítulos posteriores emplearemos este procedimiento para comprender los resultados que ocasiona.
Ponderar (![]() ): A través de esta opción, podemos asignarle un peso o valor diferente a cada uno de los casos; es decir, darle mayor importancia a unos valores de registro que a otros, esto se hace con el fin de poder sacar algún resultado representativo de la población y no de la muestra. Para poder realizar este procedimiento, es necesario tener una variable de ponderación en la cual se encuentran los valores (Pesos) de cada registro; en capítulos posteriores emplearemos esta opción para comprender los resultados que ocasiona.
): A través de esta opción, podemos asignarle un peso o valor diferente a cada uno de los casos; es decir, darle mayor importancia a unos valores de registro que a otros, esto se hace con el fin de poder sacar algún resultado representativo de la población y no de la muestra. Para poder realizar este procedimiento, es necesario tener una variable de ponderación en la cual se encuentran los valores (Pesos) de cada registro; en capítulos posteriores emplearemos esta opción para comprender los resultados que ocasiona.
Seleccionar casos (![]() ): A través de esta opción, podemos seleccionar solamente los casos que cumplan con los criterios que el investigador imponga; por ejemplo, las personas del género femenino. A su vez, este procedimiento nos brinda la oportunidad de pedirle al programa que tome un fragmento de los casos de forma aleatoria. Al activar la selección de casos el programa realiza los cálculos de los procedimientos sólo con los casos que hayan sido seleccionados.
): A través de esta opción, podemos seleccionar solamente los casos que cumplan con los criterios que el investigador imponga; por ejemplo, las personas del género femenino. A su vez, este procedimiento nos brinda la oportunidad de pedirle al programa que tome un fragmento de los casos de forma aleatoria. Al activar la selección de casos el programa realiza los cálculos de los procedimientos sólo con los casos que hayan sido seleccionados.
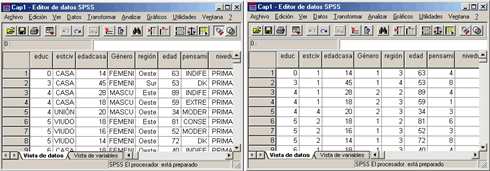
Etiquetas de valor (![]() ): Esta opción nos permite observar en el editor de datos, los valores de los datos o la categoría a la que corresponde. Al activar esta opción aparecen en el editor de datos las categorías (palabras) de cada una de las variables [Fig.1-27]. Si por el contrario desactivamos esta opción, aparecen en el editor de datos los números (Valores) de cada variable [Fig.1-28]. La utilidad de esta opción radica en la capacidad de darnos información sobre los datos que contiene cada una de las variables categóricas.
): Esta opción nos permite observar en el editor de datos, los valores de los datos o la categoría a la que corresponde. Al activar esta opción aparecen en el editor de datos las categorías (palabras) de cada una de las variables [Fig.1-27]. Si por el contrario desactivamos esta opción, aparecen en el editor de datos los números (Valores) de cada variable [Fig.1-28]. La utilidad de esta opción radica en la capacidad de darnos información sobre los datos que contiene cada una de las variables categóricas.
Usar conjuntos (![]() ): Este procedimiento nos permite generar o utilizar conjuntos de variables, para restringir el número de variables mostradas en las listas de origen de los cuadros de diálogo. Los conjuntos de variables pequeños hacen que la búsqueda y la selección de variables para los análisis sea más fácil y pueden incluso mejorar el rendimiento. Si el archivo de datos contiene un elevado número de variables y los cuadros de diálogo se abren con lentitud, es necesario restringir las listas de origen de los cuadros con subconjuntos de variables más pequeños, lo que reduce la cantidad de tiempo empleado en abrirlos.
): Este procedimiento nos permite generar o utilizar conjuntos de variables, para restringir el número de variables mostradas en las listas de origen de los cuadros de diálogo. Los conjuntos de variables pequeños hacen que la búsqueda y la selección de variables para los análisis sea más fácil y pueden incluso mejorar el rendimiento. Si el archivo de datos contiene un elevado número de variables y los cuadros de diálogo se abren con lentitud, es necesario restringir las listas de origen de los cuadros con subconjuntos de variables más pequeños, lo que reduce la cantidad de tiempo empleado en abrirlos.